Software Delivery at Scale: The Newfire Model

One of the first things we do when encountering an existing project is to look closely at how code gets delivered. From seeing which processes work (and which don’t) across hundreds of engineering teams, we’ve come to understand broadly applicable best practices that allow teams to deliver consistent value to end users. A crucial pattern here is a branching and delivery methodology that accelerates results, reduces risk, and fosters collaboration across teams.
Leading teams of Newfire engineers, we have applied this pragmatic approach to trunk-based development across various projects, particularly in multi-tenant SaaS applications, to help clients innovate rapidly while keeping code quality high. As we like to say, “Move fast and don’t break things.”
Whether you’re considering Newfire to strengthen your delivery capabilities or seeking a proven foundation for your own engineering organization, we’ll show you how our branching model works and how it can fit into your organization’s delivery process.
How Did We Get Here? A History of Git Branching
Git’s defining feature, zero-cost branching, made it (nearly) free to create branches, even in large codebases. This allowed developers to work in isolation, enabling safer changes and true parallel development. It took a few years for the industry to realize how fundamentally this capability changed the way software was built and teams collaborated.
GitHub’s launch in 2008 and its rapid adoption within the open source community helped bring Git to a broader audience. This sparked widespread discussion around branching models and how best to use them.
The GitFlow model emerged in 2010, promoting itself, in the words of its creator, as something “which has turned out to be very successful.” Thanks to its clear process recommendations GitFlow quickly gained popularity and became the de facto standard of branching models.
Now, however, even the creator of GitFlow feels it’s not the right fit for a lot of today’s software. Alternatives like GitHub Flow attempt to simplify GitFlow’s model, but in doing so, leave many decisions up to the implementer, making their overall effectiveness highly dependent on the outcome of those decisions.
Teams that attempt to “adopt” GitHub Flow are forced into many of the same branching model discussions that bogged down development in the early days of Git. Over time, teams realized that both GitFlow and GitHub Flow had significant limitations, either being too cumbersome or too vague to guide real-world delivery.
Trunk-Based Development has become the preferred branching strategy for high-performing teams. However, fully adopting this practice requires significant investment in systems architecture, deployment processes, and monitoring systems. Additionally, it may not be compatible with all security or compliance processes that are currently established. In our experience, seasoned teams attempting to adopt trunk-based development often receive pushback due to these factors.
At Newfire we’ve developed a pragmatic take on trunk-based development that balances structure with flexibility. The result is a workflow that supports fast iteration, stable releases, and strong collaboration across teams while being adaptable enough to fit within your current deployment and compliance processes.
Newfire’s Take on Trunk-Based Development
Our approach builds on the basic trunk-based development method’s foundation in continuous integration and reinforces it with a robust review process. This adds a layer of security while also providing opportunities for team collaboration and skill development.
While traditional trunk-based practices advocate for only one main trunk branch, our model centers around a set of Integration Branches—long-lived branches where code developed in parallel is brought together into a unified codebase. In SaaS projects, these branches often align with environments like dev, staging, or prod.
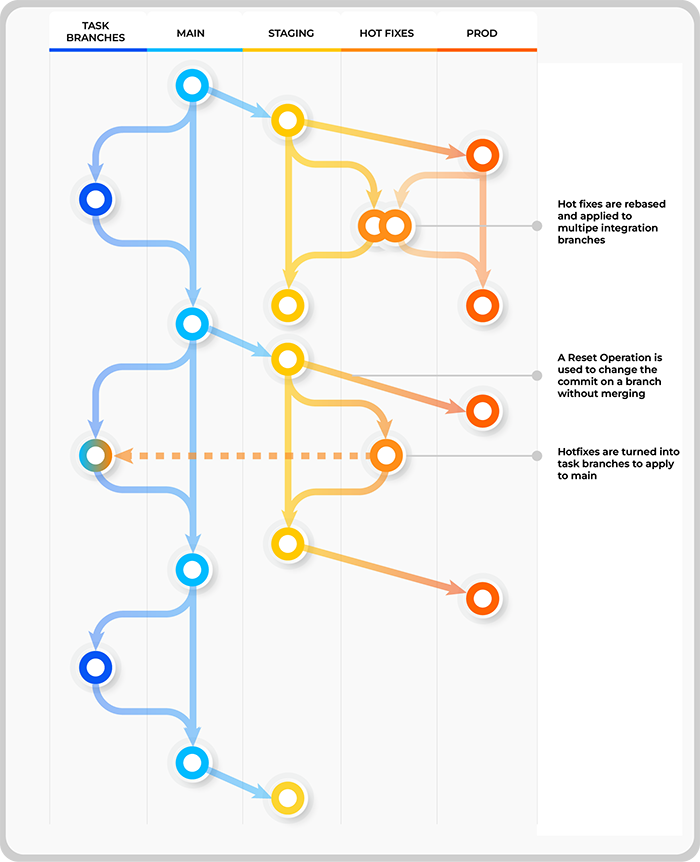
In other contexts, such as large-scale platforms or products under regulatory oversight, they might represent major versions or significant features awaiting approval. By anchoring development to these clearly defined integration targets, we enable safe parallel workstreams while maintaining a consistent path toward production.
To make this work in practice, we combine a few carefully chosen constraints. In addition to protected integration branches, we enforce automated checks and a required review gate. These are paired with lightweight developer habits that keep code flowing. It’s this balance of appropriate guardrails and flexibility that lets the model scale across different teams and environments.
The following are the key elements that define how this branching and deployment model functions in practice:
- We use different integration branches. These branches are protected so that code cannot be merged directly into them. main should be the primary development branch. Branches such as staging and prod should correspond to different integration targets.
- Developers branch off of the integration branch they want to target, creating a task or hotfix branch. Work on a single small task is done in isolation on this branch.
- When a developer’s work on the task is complete, they rebase their branch against the integration branch and open a pull request (PR) to that integration branch.
- PRs are merged into the integration branch following a review and automated checks.
- Commits to an integration branch trigger a build and deployment to the appropriate environment. These builds are tagged with the commit SHA from which they were built.
By using short-lived branches, automated processes, and targeted reviews, we apply trunk-based development principles in a practical, efficient way.
The payoff is clear: faster delivery through short-lived branches and automated promotion; lower risk, since integration branches never diverge; and better team collaboration enabled by lightweight reviews and continuous integration.
Integration, not Release Branches
Our model focuses explicitly on integration branches rather than release branches. These are long-lived branches that are targets for code integration. One important distinction is that our model does not differentiate these branches from our “development” branch, meaning there is no difference in the process being used to integrate a hot-fix for the current production system and the process for a new feature in development.
For a company that is new to trunk-based development trying to determine which integration branches will be needed, we suggest starting by looking at the number of environments already in use and considering both the cadence of deployments and the general tolerance of something being broken.
For instance, let’s assume a system where every change an engineer makes is automatically deployed to a development environment, there are nightly deployments to a QA environment, weekly deployments to UAT, and a production deploy every two weeks.
In this scenario, three integration branches would be called for:
- main targeting the development environment, and the QA environment. We would accept the risk that the daily QA release may be broken and not get fixed until the next regular deployment.
- uat targeting the UAT environment, allowing for hot-fixes during the time between regular deployments.
- prod targeting the production environment.
Here is a simple diagram of this workflow:
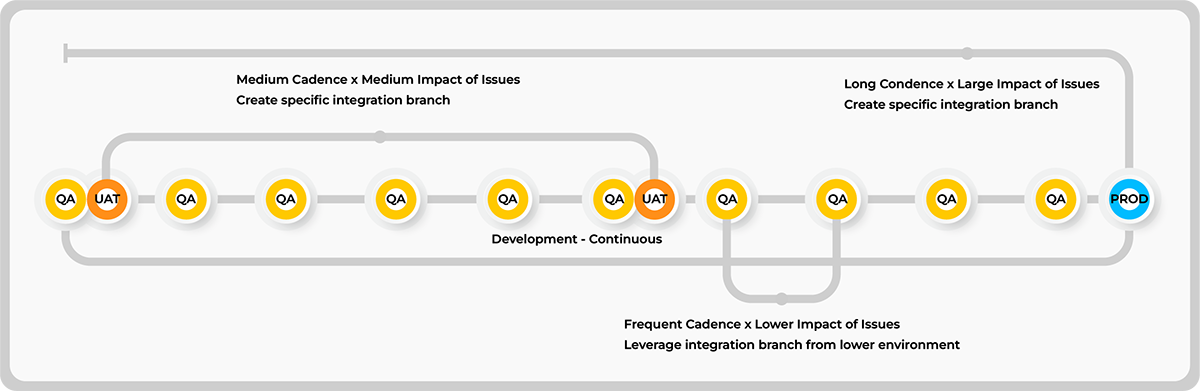
By focusing on integration rather than release branches, teams can simplify their delivery model, align development with deployment cadence, and reduce complexity without sacrificing flexibility or control.
Why Our Approach Works
Our branching model strikes a balance between prescriptiveness and adaptability and thus works across a wide range of teams, projects, and delivery environments.
The prescriptive parts (protected integration branches, automated checks, and a mandatory review gate) create a reliable backbone for quality and security. The adaptive parts (short‑lived task branches, fast merges, and the freedom to map integration branches to dev, staging, prod, or even regulatory milestones) let teams iterate quickly without getting bogged down in process debates.

Because of that balance, the workflow scales cleanly across very different contexts. We’ve run it on lean startup teams racing to ship new SaaS features and on large, mature codebases that need tight compliance controls. In both cases, engineers can work solo or in pairs and still land code in a single, unified trunk without the overhead associated with long‑running feature branches.
The payoff is threefold:
- Faster delivery: short branches plus automated promotions keep code flowing from commit to deploy.
- Lower risk: integration branches never diverge, so hotfixes don’t become multi‑day cherry‑pick marathons.
- Better collaboration: formal but lightweight reviews spread knowledge and raise code clarity across the team.
These results don’t happen by accident. They’re reinforced by consistent habits, thoughtful tooling, and a culture that values clarity, speed, and shared responsibility. It’s an approach we’ve refined (and continue to evolve) through hands-on delivery across teams, tech stacks, and client environments.
Bringing It All Together: A Proven Model for Scalable Delivery
At Newfire, we’ve refined this branching and deployment model through years of hands-on experience with complex systems and fast-moving teams. It’s designed to support rapid iteration, reduce delivery risk, and foster healthy collaboration, outcomes that are critical for any engineering leader responsible for building sustainable, high-performing systems.
Whether you’re looking to augment an existing team or launch a new product, our approach gives you a reliable foundation to move fast without losing control. Want to explore how this model could work inside your organization? Get in touch and let’s talk.
Chris Pardy is a director of engineering on Newfire's Advisory Services team. He has led engineering teams at high-growth startups and established tech firms, including Own Up, RateGravity, and Fitbit, since 2009. He excels in scalable systems, innovation, and user-focused solutions. Proficient in AWS, React, Microservices, Typescript, Python, and Java, Chris drives success from startups to IPOs with a focus on technical excellence.

