Multi-cloud: To Be or Not to Be How do companies utilize cloud technology?

Take into consideration a small startup company with no more than an idea in hand and a few willing investors to back it up. Imagine paying for a GPU server unit (a few thousand dollars and upwards) to run a machine-learning model for several hours, only to leave it idle 80% of the time after that. And I’m not even including the wait time for it to arrive (a few weeks or even months) or the expertise required to configure and maintain it. Buying a set of specialized hardware that may or may not be used later on is a huge budget killer (part of Capital Expenditure or CAPEX).
So most of them will use cloud providers and rent the compute power from them, as it allows the company to pay for only what they use in day-to-day operations (Operating Expenses or OPEX). You simply choose the required compute power level, deploy it, run the workload, and after you are done, destroy it.
On the other hand, some medium to large companies will utilize cloud alongside their on-premise infrastructure in a so-called hybrid architecture. They are keen on working on their core business and don’t want to waste time and money on re-inventing the wheel with already existing services. For example, managed databases, infinitely scaling storage, serverless offerings, and so on. A CAPEX model with on-premise infrastructure makes sense for them due to sheer size and long-term commitment where it’s a lot cheaper to run things.
I’m already using multi-cloud
Actually no, you probably aren’t.
A lot of companies, whether they have some on-premise infrastructure or not, use a wide range of services from other companies. It’s either not their core business so there’s no point in creating their own solution, or perhaps the service is just better, cheaper, easier to use, etc. For example, one can use Atlassian Jira for project management, Gitlab or Github for hosting their code repositories, Zoom or Microsoft Teams for video conferencing, Google Suit for emails, and the list goes on. This could be considered a best practice, however note that despite varying providers and platforms, that is not considered an actual multi-cloud strategy.
Is multi-cloud on purpose or
can we just not avoid it?
Some organizations are “multi-cloud” without even having that in their business strategy. They simply end up with infrastructure being hosted on two or more cloud providers over time.
That can happen for several reasons: a particular service is not available with their primary cloud provider; it is not stable enough; it lacks several key features; it costs a lot more money; it’s not yet available in a specific region where most of the clients are situated and so on.
Others embrace that type of strategy and align it in accordance to business needs and benefits. Lower operational costs, closer customer presence, and agile on all fronts. Those are just some of the reasons and needs why somebody would go with multi-cloud.
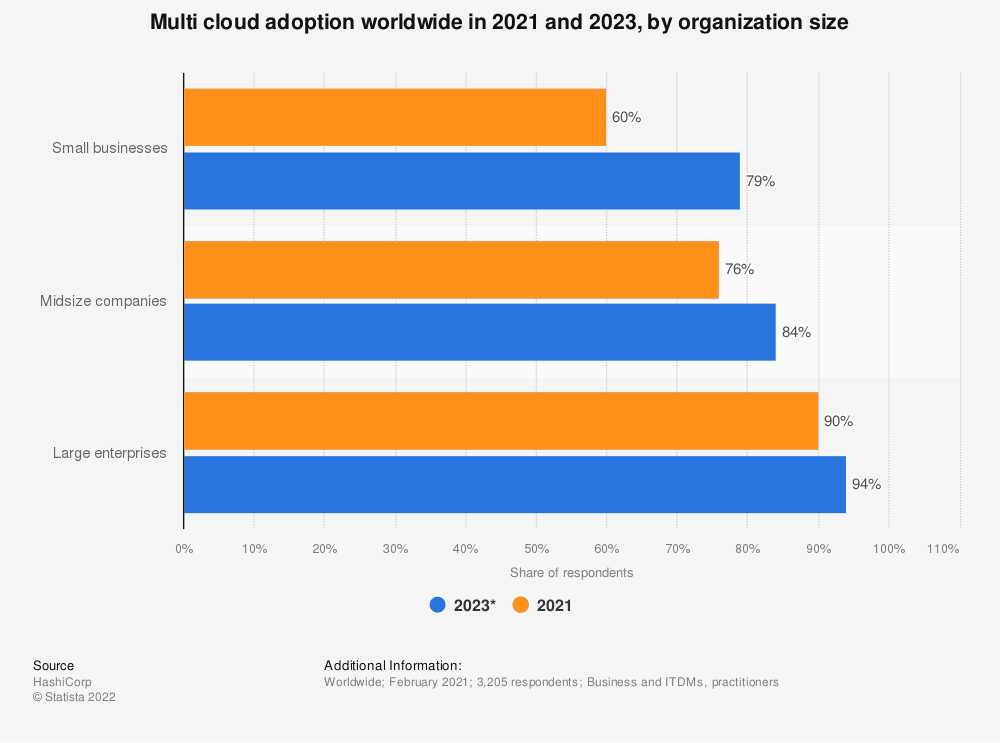
source: statista.com
Why use multi-cloud?
For a variety of different reasons, a well-managed multi-cloud strategy allows the luxury of freedom to migrate their workload with ease between different cloud providers. It allows organizations to benefit from certain provider strengths while neutralizing their weaknesses.
One of the biggest reasons is definitely regional availability. While major public cloud providers have a wide global footprint, a combination of them is simply vast, covering all corners of the globe. Many of them offer specific local zones very close to possible clients. And getting service as close to the customer as possible can greatly affect its performance advantage and customer satisfaction.
When we are sure that we are following common best practices like this for example, an upgrade to it can be a multi-cloud strategy to further increase our data resiliency and service high-availability. Different cloud providers are hosted in different datacenters, connected to their dedicated network links, cooling, power supply, and on different hardware.
From the security standpoint, It can greatly increase the resiliency of our service to DDoS attacks.
With pushing the multi-cloud strategy, we are making sure services are agnostic to underlying infrastructure/platform and helping to avoid vendor lock-in.
In some cases, cloud providers can become a single point of failure as they can have incorrect configuration changes, outages caused by hardware failures, and so on. A lot of it depends on the specific region. Yes, region, not regions, as with AWS Virginia (us-east-1). And there is nothing you can do about it but sit and wait.
Data sovereignty requirements can be achieved for different geographies as we can easily transfer to local data centers/providers if necessary.
Cost optimize by utilizing short-term virtual machine instances (AWS spot VM, Azure low-priority VM, Google preemptible VM) and switching the workload depending on the current prices.
Why avoid multi-cloud?
Despite the multitude of benefits for using multi-cloud, there are also negative aspects that we should take into consideration.
Starting with security, exposing an organization on multiple fronts as their data is flowing in and out of additional networks and providers will require a lot more attention to details and policies. All of this will add to time and effort that needs to be involved to follow best practices while knowing the tiny bits and pieces that each cloud provider suggests on their platform.
That brings us to the next item: complexity and engineering man-power. Maintaining and designing a scalable, stable, and secure service is one thing, but making it cross-platform is another.
Engineers that have the experience and knowledge with multi-cloud setup are harder to find and finding additional experts to plug knowledge-gaps will definitely increase costs. There are a ton of tiny bits and pieces that need to be learned and are specific to a cloud provider and their services. Complexity can be reduced to some degree with cloud-agnostic Infrastructure as code tooling like [Terraform](https://www.terraform.io/ ) or [Pulumi](https://www.pulumi.com/). Or if your workload consists of microservices running in containers, there are a lot of systems like [Kubernets](https://kubernetes.io/) that offer a high abstraction layer and hide some of the specific cloud platform complexity from the end-user.
Finally, cost is definitely a factor that should not be overlooked. A huge factor in any cloud provider bill is the egress (or outgoing traffic cost). All of them will lure you in and ingest your data free of charge, but getting it all back is where they earn their paycheck. This is true even for the single-cloud setup if a multi AZ/multi region setup is used, but it should be considered as the bill can only grow higher.
From the cost optimization side, if you use short-term virtual machines, you’ll likely benefit from hopping across multiple cloud providers. But for long-term virtual machines, you can get vast discounts (up to 60% and more) for utilizing reservations. Cloud providers love when a customer has more predictable growth and knows that it will purchase their compute power for a several year period. With less virtual machines hosted there, as you have spread the load on multiple providers, you lose the possible volume and long-term discount.
Other than that, adapting to a multi-cloud platform will require organizations to fall back on the lowest common denominator with offered features. Not all services are the same and offer the same capabilities. While some are in the preview phase, others are production-grade and battle-tested. We cannot expect, for example, a compute instance with the same power-ratio (Memory/CPU) on every platform, a serverless runtime with a specific programming language and version, or a load balancer with a specific traffic distribution algorithm.
Vendor lock-in
There are a lot of interesting subjects on this topic, most pointing to the negatives. But can it be avoided anyway? You should take whatever suits you the best and start with that. As Donald Knuth said “Premature optimization is the root of all evil.”
Software is like a living creature. It evolves with time. Follow best practices, monitor your business and infrastructure needs, and adapt as you go. There are a lot of things to consider when designing a service that can adapt to changes like that, but the gains can be substantial in the long run. One of the biggest benefits is that it will get you one step closer to a multi-cloud strategy and a simpler lift-and-shift architecture whenever there is a chance or a necessity to do it.
Take for example, AWS S3, one of the biggest cloud wins for any company utilizing it. A virtually infinitely scaled storage, a set of tools for third-party developers to use and manage it (SDK), and did I mention 99.999999999% of annual data durability? That means that if you store 1M objects for 10 million years, chances are only one would get lost. Similar service is also offered by other major cloud providers including Google storage, Azure Blobs, and DigitalOcean Spaces.
On that note, a great example would be the reverse-migration step that Dropbox did, moving from AWS to their on-premise infrastructure and thoughts and lessons learned 5 years later.
Can you trust a single cloud provider?

Let’s not forget that the cloud is not some magic place where everything is great and flourishing. After all, there are still servers running underneath it all, maintained by engineers like us.
Yes, that is their core business and they probably use specialized enterprise-grade hardware that can withstand running 24x7x365. With proper cooling, power supply, advanced monitoring, and a lot of knowledge to keep it up and running.
But accidents do happen at any given moment ranging from minor to disastrous consequences.
Maybe some of you remember the AWS outage last year that crippled a large portion of the internet for a few hours?
Or perhaps you had something hosted on OVH when their Strasbourg datacenter got destroyed in a fire
Or the Microsoft Azure outage affecting virtual machines globally for over several hours?
A multi-cloud strategy could come in handy in those situations. However, it’s not a silver bullet. Off-site backups, proper resiliency, high-availability and other pillars of good architecture are primarily what’s needed, no matter where we host our services.
Gluing all the pieces together to keep the monster at bay
So, you decided to walk the multi-cloud path.
As mentioned, a proper “Infrastructure as Code” practice is a must. There are already a few production-tested tools out there like Terraform and Pulumi. Both require learning a single language or syntax, have lively and active communities, and their end-user interface is easier to maintain than handling large YAML or JSON files in the native IaC tooling that cloud providers offer.
For some organizations, it may make sense to either use or implement their own cloud management platforms to have a single point of entry for their employees. This hides a chunk of complexity and overhead with the abstraction layer, and allows both operations and development teams to handle and use a multi-cloud platform with more ease.
PaaS solutions, like Kubernetes, also provide an abstraction layer that allows for an easier lift-and-shift workload and most of the global cloud providers host that variation, which provides a similar interaction interface.
Here are some examples of PaaS k8s services on major cloud provider platforms: Google Kubernetes Engine, Amazon Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS).
To be or not to be
As with everything, there’s no one-size-fits-all multi-cloud strategy.
Do take into consideration that there are many prerequisites here: first, you should already be stretched in multi-AZ (availability zone) across multiple regions; additionally, you must have resilience implemented in application design and implementation. This will get you much closer to the multi-cloud paradigm.
Ultimately, even if an organization decides not to go with a multi-cloud strategy, following the best architecture practices will allow for an easier switch when that need or opportunity comes knocking and in the meantime, ensures that your service performs at its best.

